Lucidworks Fusion 5 Configuration
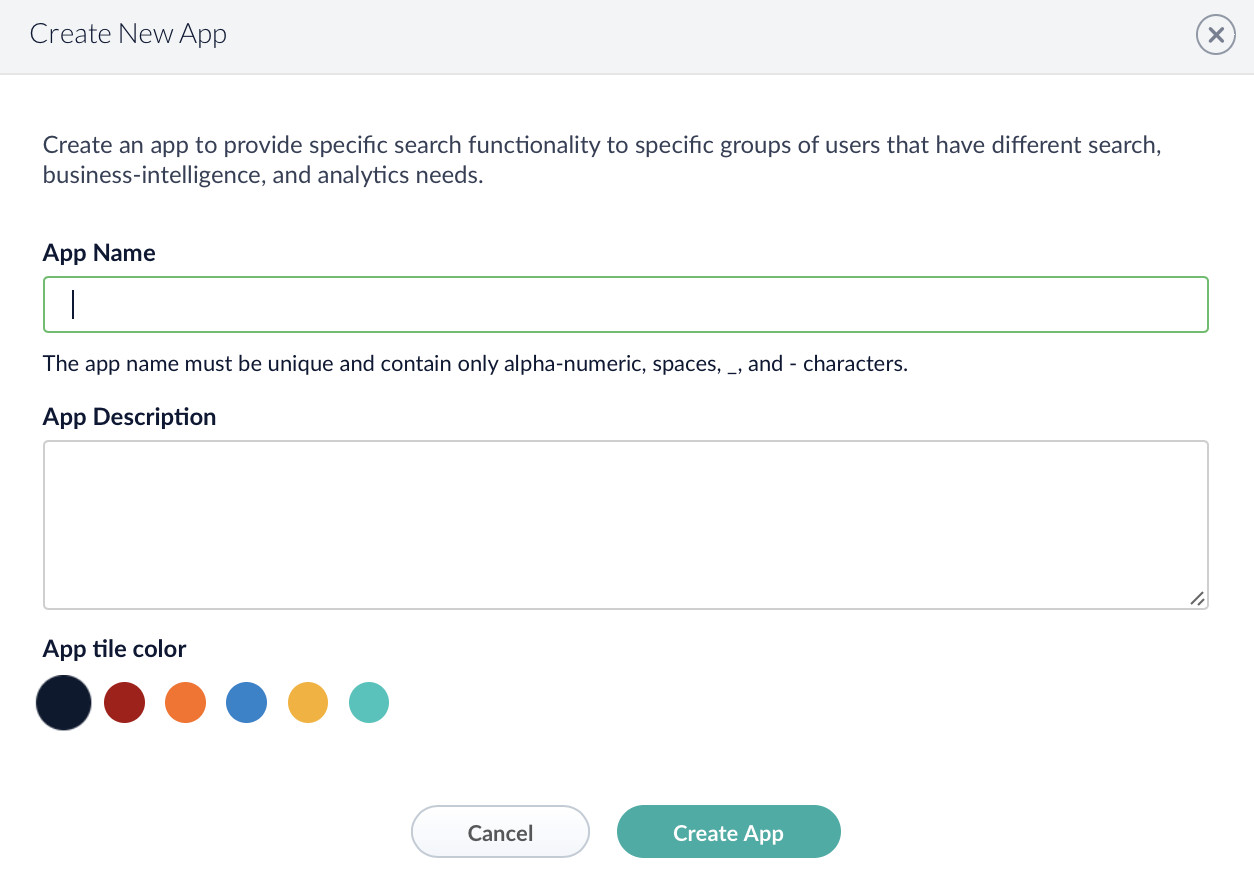
Create new App
You can skip this step if there is already an app you want to use the connector for.
Navigate to App Launcher to create a new app.
Create Technical Account
It is recommended to create a dedicated technical user account for the connector restricted to the intended API permissions.
In order to create a new user navigate to System → Access Control → Users.
The connector requires at least the API permission HEAD,POST,GET,DELETE,PUT:/index-pipelines/** to consume the Indexing Pipeline API.
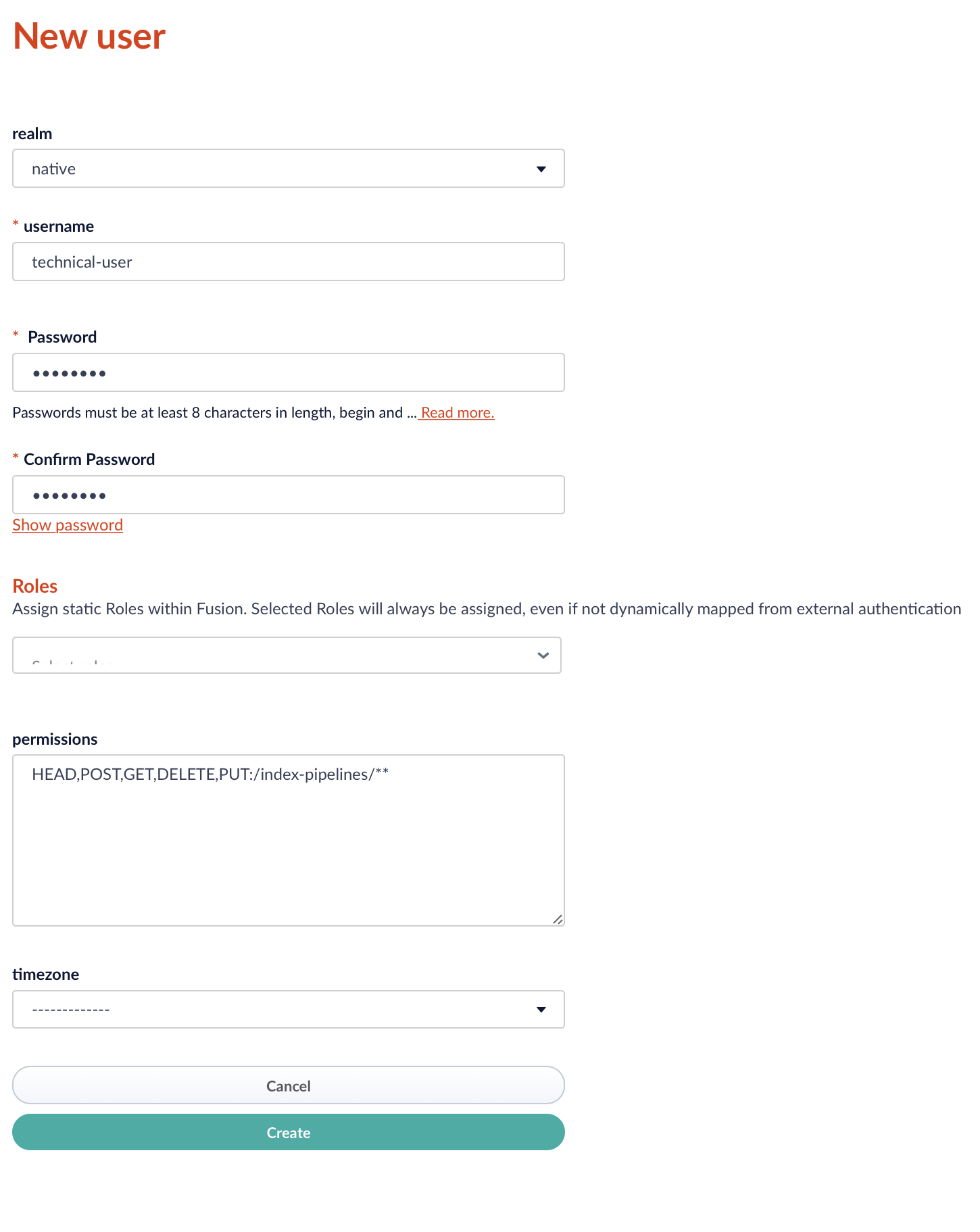
The created technical account credentials has to be specified in the connector configuration. Note, that the connector supports only the authentication via native realm.
Make sure to select the native realm when creating the technical account.
|
Configure Index Pipeline
The connector processes binary content as Base64 encoded text into target Solr collection. Hence, it is recommended to include the Tika parser into your indexing pipeline.
Create Content Collection
If you use an existing collection within your app to index your documents, you can skip this step.
To create a new collection navigate to Indexing → Collection Manager within your app.
Create Tika Parser
As the connector does not apply any advanced binary content processing before indexing the documents, it is recommended to
use the Apache Tika Parser provided by Fusion.
Navigate to Indexing → Parsers → Add+ to add a new parser to your app. Remove all default parsers and add the Tika Parser to the list of parsers.
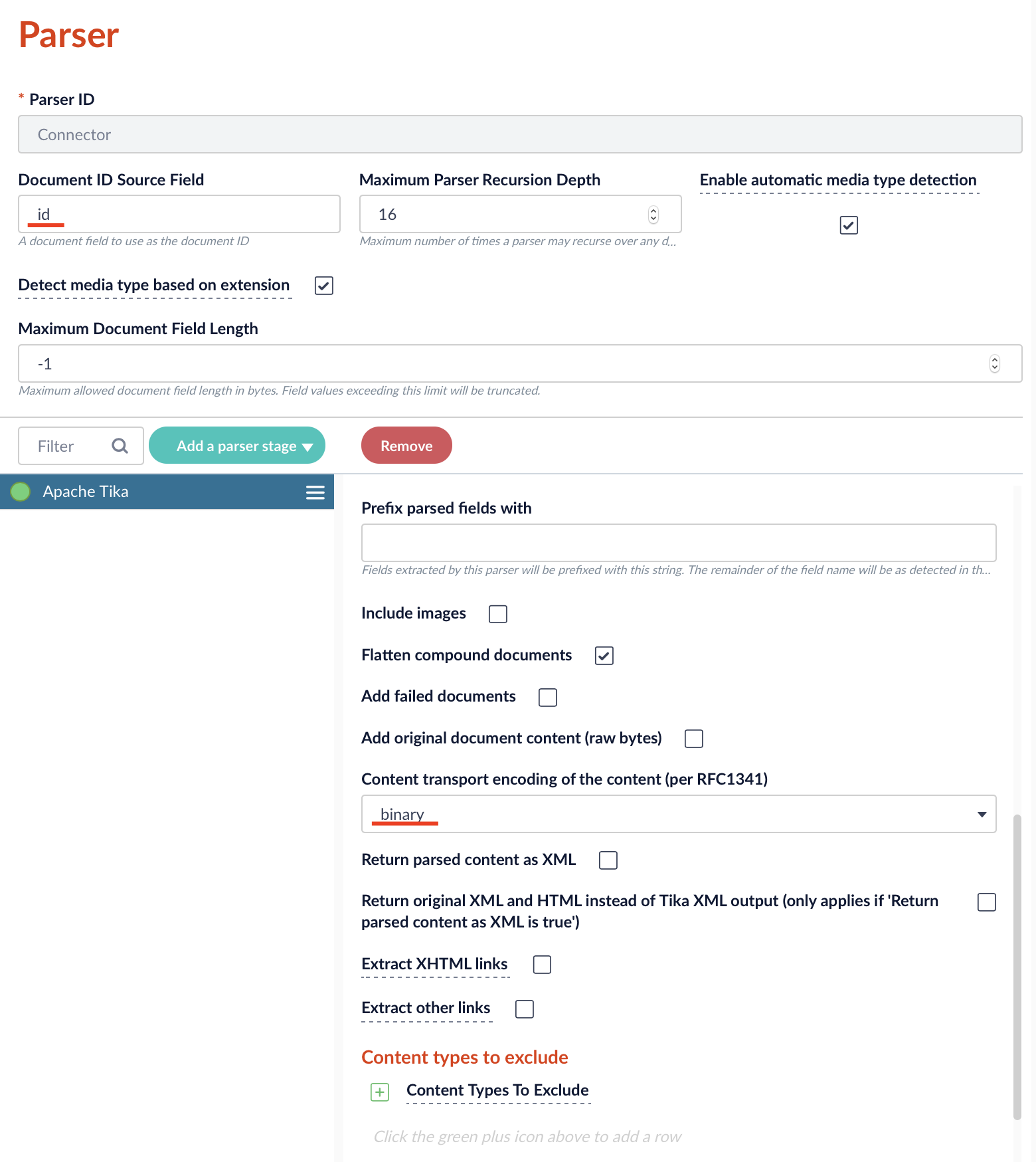
Set the Document ID Source Field to id and set the content encoding to binary.
Include the Parser to Index Pipeline
Navigate to Indexing → Index Pipelines.
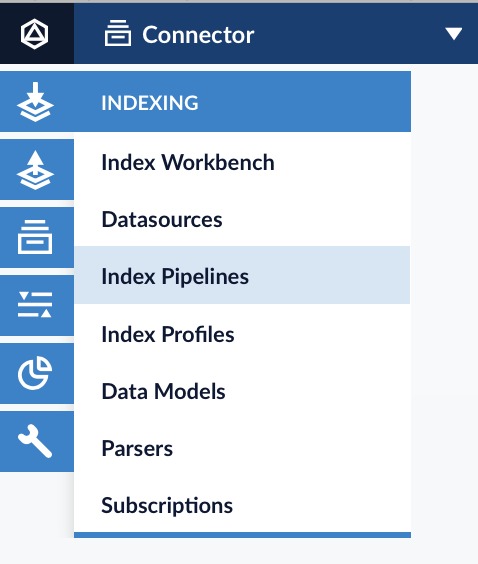
Include the Field Parser Stage to your pipeline. Set the Parser ID to the ID of the parser created in previous step.
Make sure to set the Source Field to raw_content and Source Field Encoding the base64.
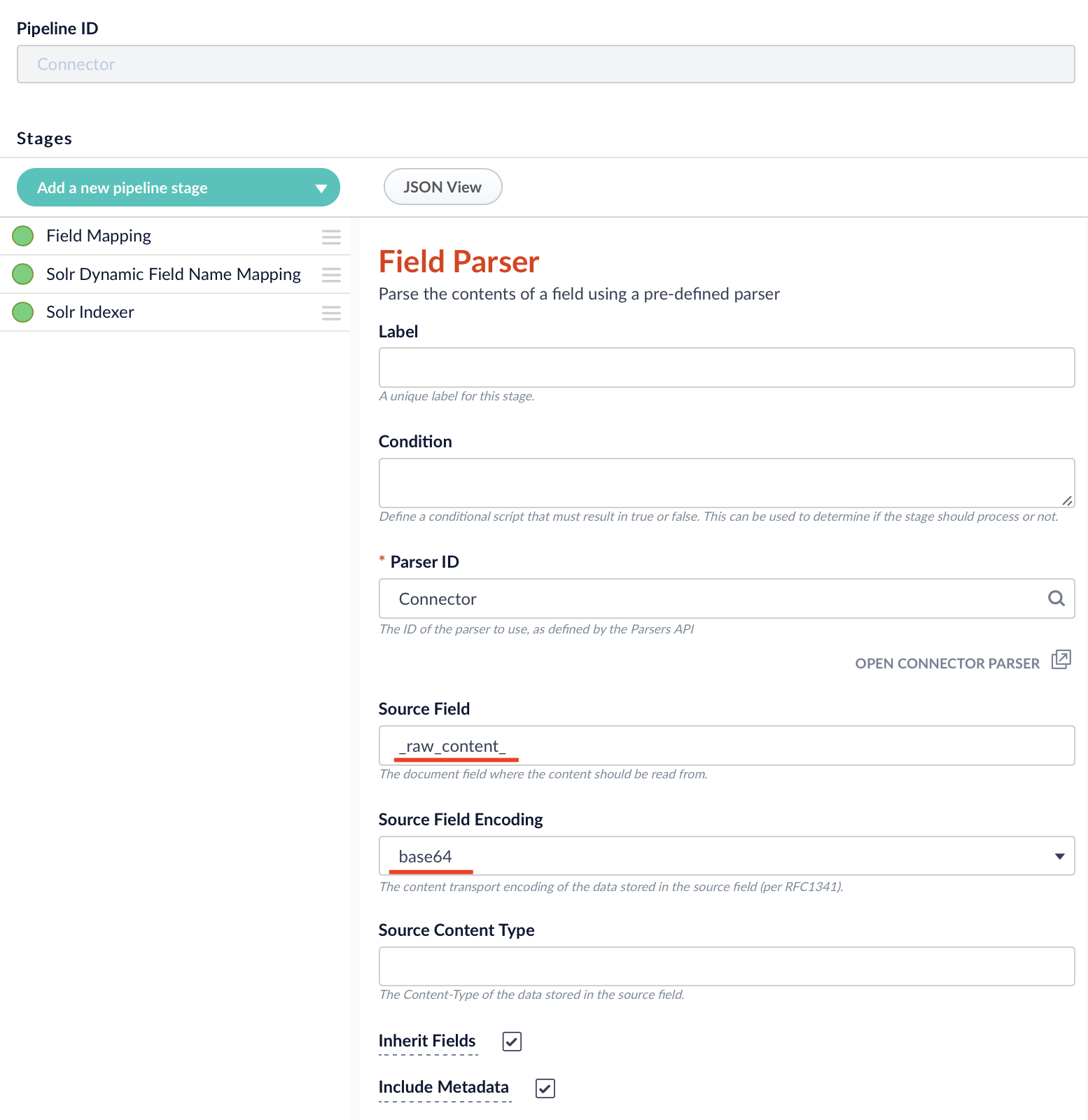
The configured Index Pipeline has to be specified in the connector configuration under Basic → Lucidworks Fusion 5 → Indexing Settings → Indexing Pipeline.
|
Configure Principal Index Pipeline
In addition to the content collection, the connector requires a separate collection and index pipeline for indexing principal information to Fusion.
Create Principal Collection
If you use an existing collection within your app to index your documents, you can skip the step.
To create a new collection navigate to Collections → Collection Manager within your App launcher.
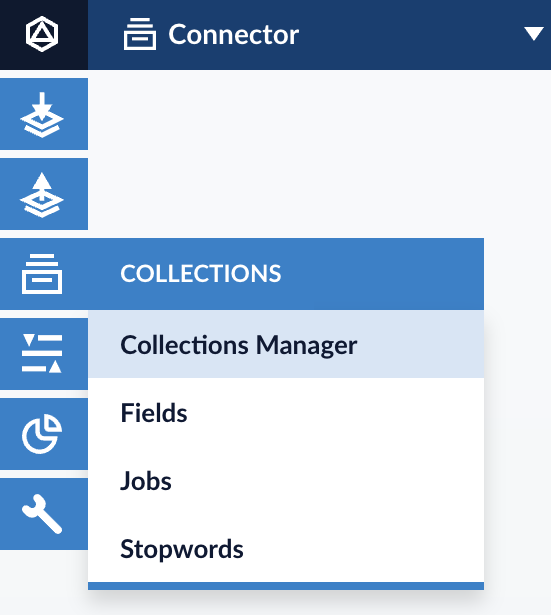
Create a new principal collection by typing the collection name and submitting Save Collection.
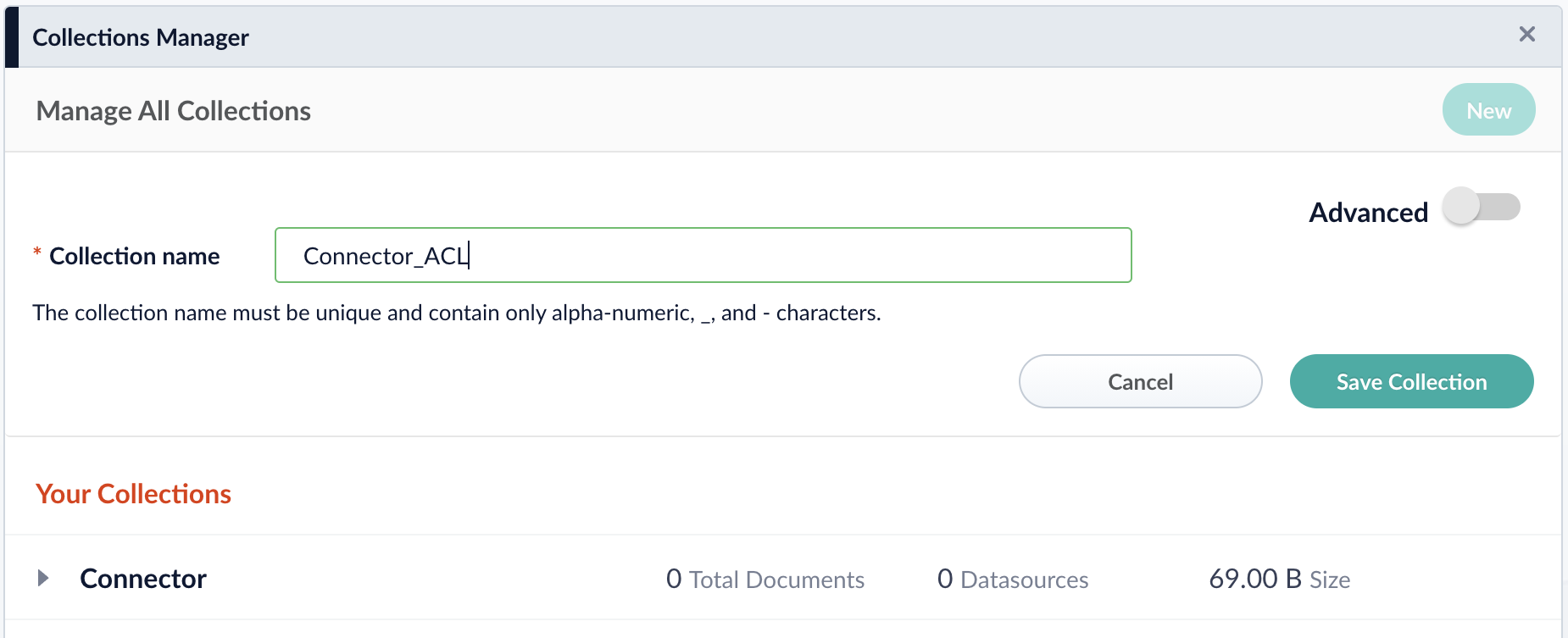
Create Indexing Pipeline
If you have already a indexing pipeline attached to your principal collection, you can skip this step. Note, that you should not reuse the content indexing pipeline, but maintain separate pipelines for content and principal indexing instead.
Navigate to Indexing → Index Pipelines.
Create a new index pipeline by typing the ID and Save. Keep the default settings and stages.
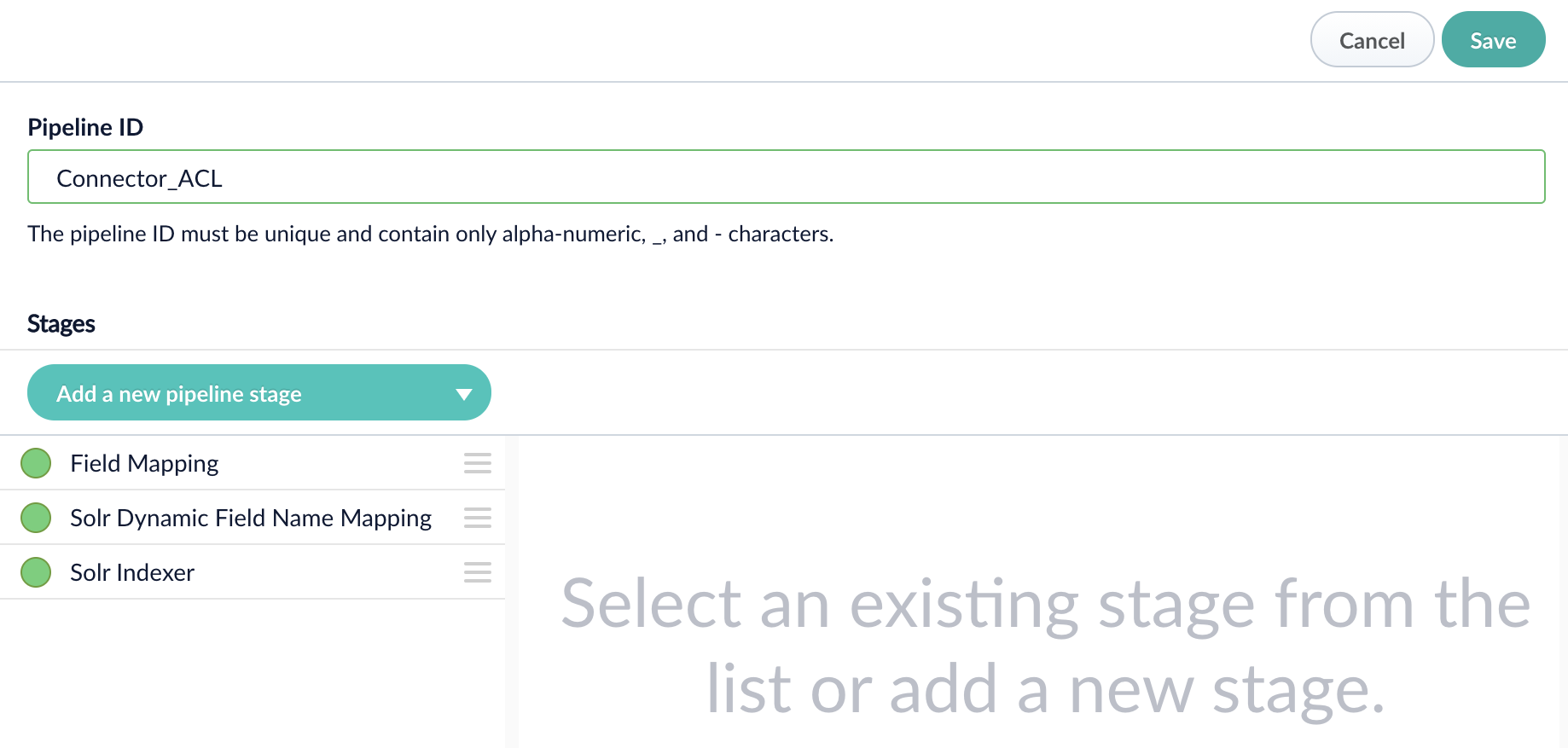
Configure Query Pipeline
Raytion Security Trimming Stage
If your Fusion Query Pipeline does not include the Security Trimming Stage, it will return all documents that match the search query.
It will not consider the Access Control of the indexed documents. Upload the Raytion Security Trimming Stage as Managed Javascript Query Stage and include it into your query pipeline.
The stage can be found at /scripts as raytion-security-trimming-stage.js inside your connector installation.
To upload the stage, navigate to System → Blobs within your App.
Select Managed Javascript (Query) and upload the file raytion-security-trimming-stage.js.
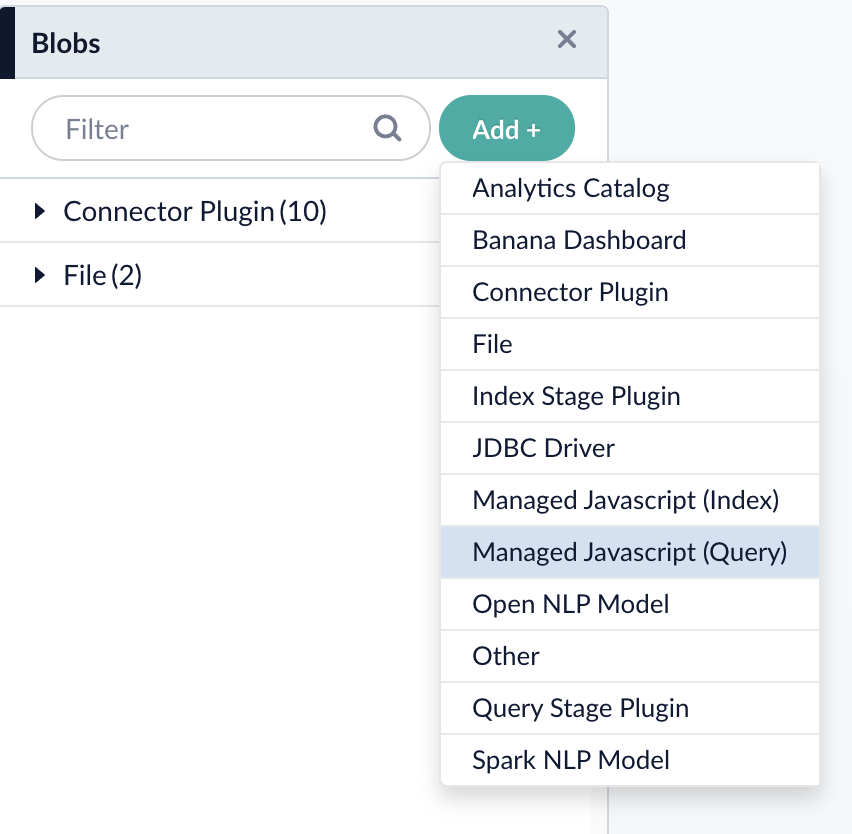
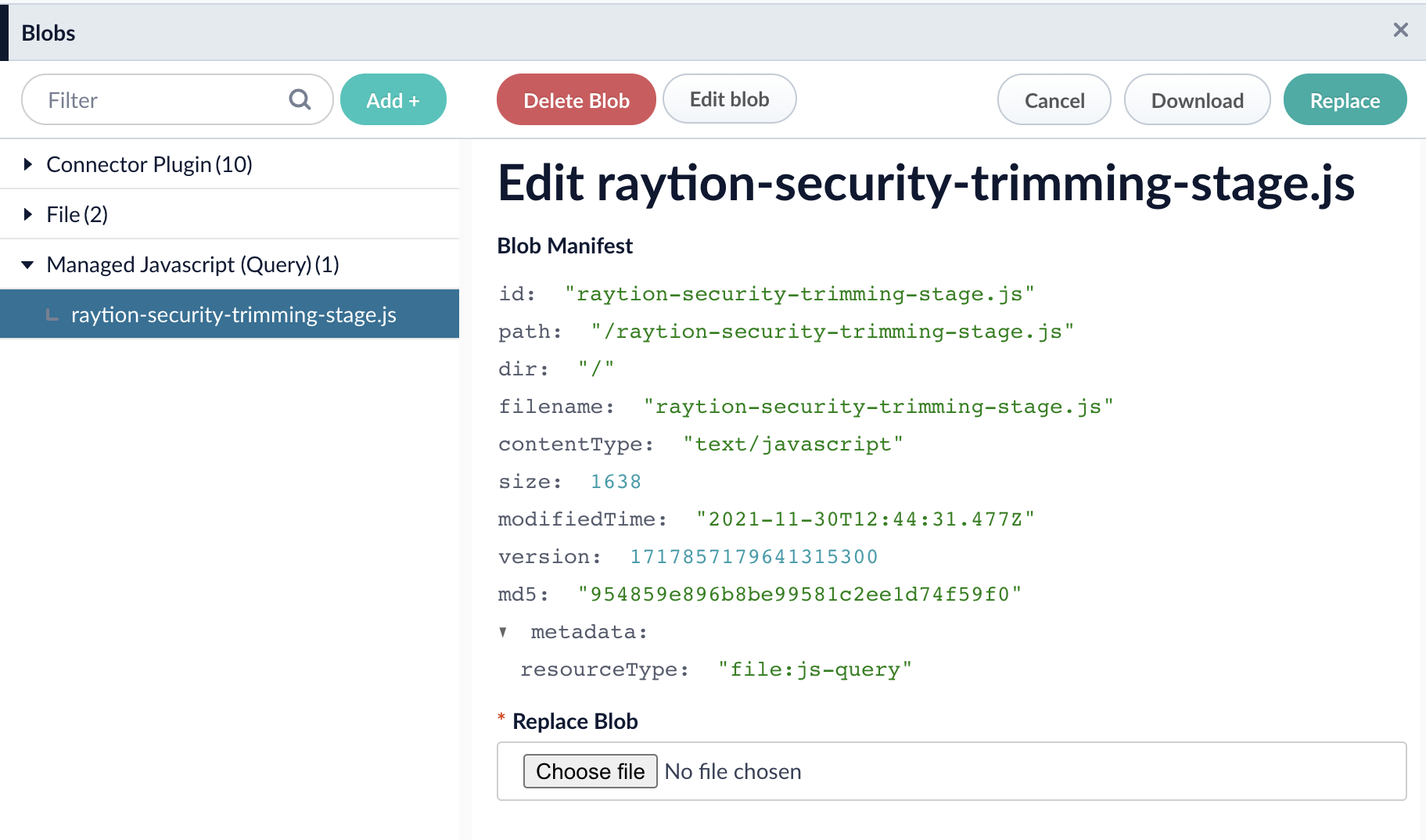
Once the file is uploaded, it can be configured in your query pipeline.
Navigate to Querying → Query Pipelines.
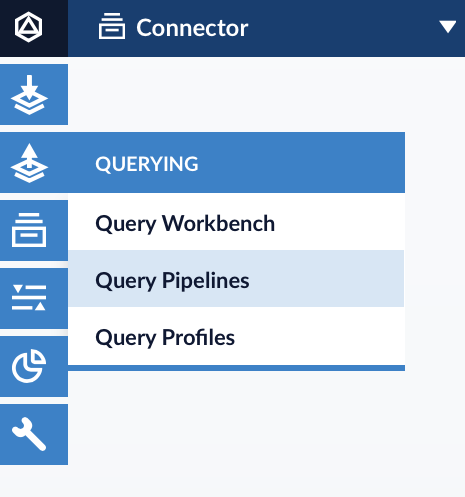
Click on Add a new pipeline stage and select Managed Javascript.
Select the file raytion-security-trimming-stage.js.
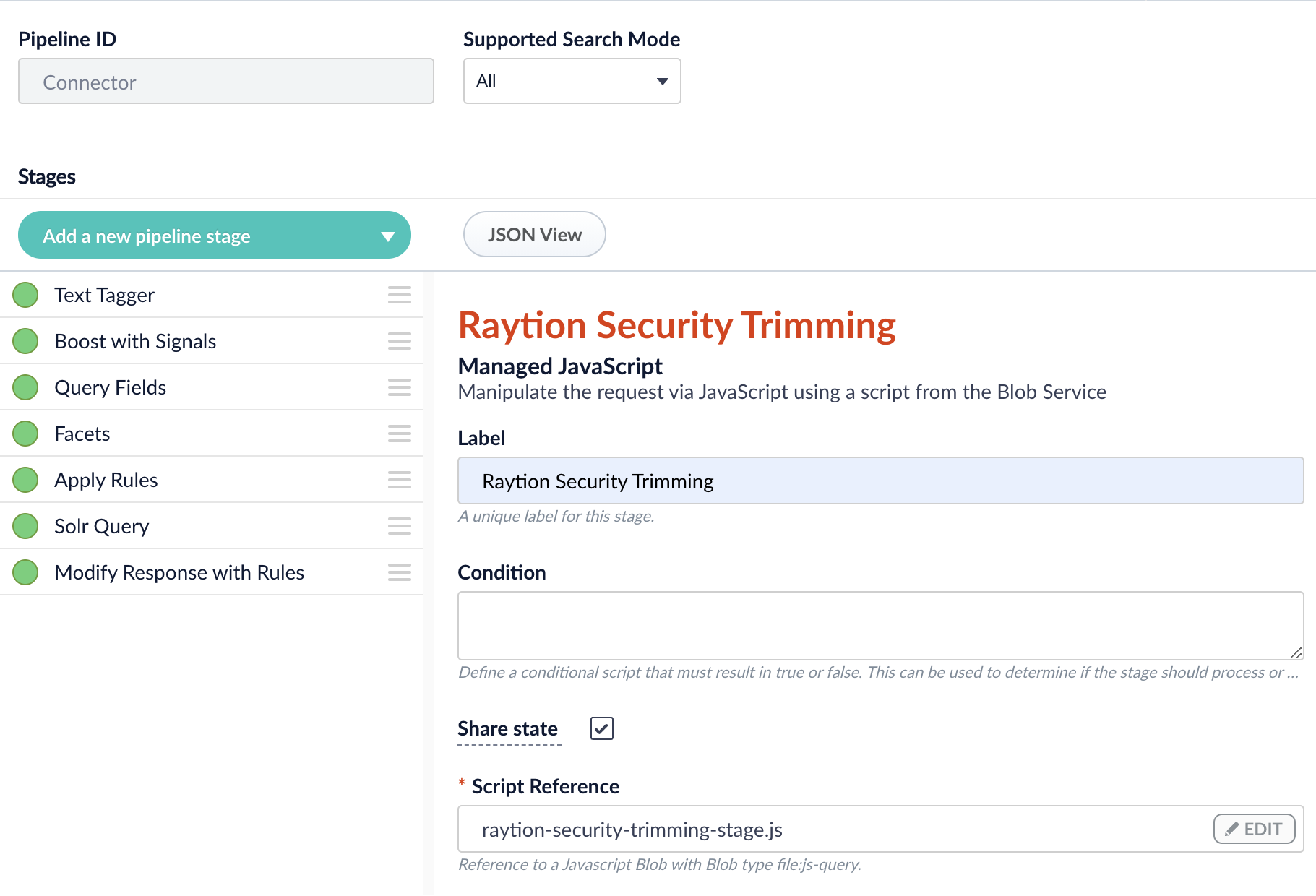
The stage expects following request parameters to be set:
| Parameter Name | Description |
|---|---|
username |
Username for the search user. This value needs to match the |
sidecar |
The name of the principal collection configured at step: Create Principal Collection |
datasource (optional) |
The ID of the datasource configured in the connector configuration under |
Within your Query Workbench you can set them in the parameter list as shown in the screenshot below.
| Without the Raytion Security Trimming Stage, all items will be visible through your query pipeline. Make sure to include the stage to your pipeline and to force the presence of the required parameters. |